

Data structures and algorithms are two central concepts in computing. Understanding them is a foundational step for every programmer.
Data structures are the various ways that data can be organized and stored in a computer program. An algorithm, on the other hand, is a step by step approach that can be followed to solve a particular problem with the stored data.
Simply put, data structures define how data is arranged, while algorithms define how operations are carried out on that data.
For efficient storage and manipulation of data, every program must incorporate effective data structures and algorithms.
Data structures and algorithms are not language-specific, the knowledge is applicable across different programming languages.
Data Structures Overview
For optimum access and operation on data, the data must be stored in the most effective format. Thus, the choice of a data structure is very crucial and will directly affect the performance, efficiency and overall success of a program.
Data structures are abstract models that describes how data can be organized and accessed in a computer. Each data structure defines the relationships and operations that can be performed on the stored data.
Types of data structures
There are various types of data structures, each designed for specific tasks and scenarios. The following parts highlights some of the most commonly used data structures:
-
Arrays
An ordered collection of elements with each element identified by an index. The elements occupies contagious locations in the memory.
The Python list is an example of an array.
Use Cases
- Fast access to elements using their indices.
- Ideal for situations where data has a natural order.
Limitations- Inefficient insertions and deletions
- Fixed size.
-
Linked Lists
A linear data structure whose elements are scattered across the memory. Each element in a linked list contains a link to the location of the next element.
Use Cases
- Efficient for fast insertions and deletions.
- Well-suited for situations where the size of the data structure changes frequently.
Limitations
- Inefficient access operations as it requires traversing the list sequentially.
- Requires additional memory for storing links between elements.
-
Stacks
A stack is a Last In, First Out(LIFO) data structure. The elements are added and removed from the same end, known as the "top" of the stack. The last element added is the first one to be removed. As in a stack of plates.
Use Cases
- Are normally used internally by most programming languages to manage function calls.
- Commonly used in applications to implement undo mechanisms.
Limitations
- Operations are restricted to the top of the stack.
- Not suitable for scenarios where random access to elements is needed.
-
Queues
A queue is a First in, First Out(FIFO) data structure. Elements are added to the rear and removed from the front. As in a waiting line.
Use Cases
- Used in task scheduling algorithms.
- Queues are employed in some graph algorithms like breadth-first search.
- Operating systems use queues to manage processes and allocate resources.
Limitations
- Operations are restricted to the front and rear of the queue.
- Not suitable for scenarios where random access to elements is needed.
- In some cases, queue implementations may have a fixed size
-
Priority Queues
A priority queue stores elements along with their associated priorities. Elements with higher priorities are dequeued before elements with lower priorities.
Unlike a regular queue, elements in a priority queue do not necessarily follow a strict First In, First Out (FIFO) order.
Use Cases
- Managing tasks with different priorities to ensure higher-priority tasks are executed first.
- Used in data compression algorithms where characters are assigned priorities based on their frequencies.
- Used in some graph algorithms.
Limitations
- Does not allow arbitrary access to elements.
-
Trees
Abraham ├─ Ishmael ├─ Isaac │ ├─ Jacob │ └─ Esau └─ ZimrancopyAs in a family tree.
A tree is a hierarchical data structure composed of nodes connected by edges. Each node has a parent and zero or more children, except for the topmost node, which has no parent. The topmost node in a tree is called the root, and nodes with no children are called leaves.
Use Cases
- Representing hierarchical structures.
- Used in file systems to represent directory structures.
- Used to represent mathematical expressions for efficient evaluation.
- Used for decision-making in artificial intelligence and game development.
Limitations
- Trees may require additional memory for pointers, especially in large and deep trees.
- Search performance depends on the balance of the tree. Unbalanced trees will lead to inefficient searches.
-
Hash Tables
A hash table is a data structure that uses a hash function to map keys to indices in an underlying array.
The dictionary in Python is an example of a hash table.
Use cases
- Efficient retrieval of values based on keys.
- Employed in databases to speed up data retrieval operations.
- Used in caching mechanisms to efficiently store and retrieve cached data.
Limitations
- Collisions in hash values can lead to performance degradation
- The size of the underlying array needs to be larger than the number of stored elements to avoid collisions in hash values. This may lead to potential space inefficiency.
Algorithms Overview
Algorithms are step by step set of instructions that can be used to carry out a specific computation task.
For example consider if you were to find the largest element in a list, you can:
- Initialize a variable
"maximum"to the first element of the list. - Iterate through the rest of the list.
- For each element in the list.
- If the current element is larger than
"maximum", update"maximum"with the current element.
- If the current element is larger than
- For each element in the list.
- After iterating through the entire list, the variable
'maximum'will contain the largest number in the list.
The above is an algorithm for getting the largest number in a list. As you can see, the algorithm is not language-specific, you can apply it with any programming language. The following is the same algorithm applied in a Python program.
For expressivity and to avoid ambiguity, algorithms are usually written in what are referred to as pseudocodes.
Pseudocodes are designed to be a high-level description of an algorithm by combining elements of natural language and simple programming constructs. This makes them language-agnostic and flexible, allowing a person to focus on the logic and structure of the algorithm without being tied to the syntax of a specific programming language
As a pseudocode, our previous algorithm for finding the largest element as will be as follows,
- input: A list of numbers
- LargestElement ← list[0]
- for each element in list starting from the second element do
- if element > LargestElement then
- LargestElement ← element
- if element > LargestElement then
- output: LargestElement
Flow Charts
Other than pseudocodes, algorithms can be represented visually using flowcharts. Flowcharts uses some established symbols and arrows to illustrate the various steps carried out by an algorithm.
The following figure shows a flowchart for an algorithm to print integers starting from 9 moving down to 1.
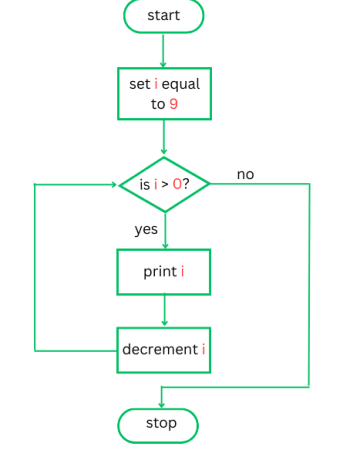
The above algorithm can be implemented as a Python program using a while loop as shown below.
Qualities of algorithms
For an algorithm to be valid it must adhere to some fundamental principles. The following part illustrates the basic qualities of an algorithm:
- Definite:
- The steps described by an algorithm must be finite meaning that the algorithm should eventually terminate. Infinite loops or processes that go on forever are not valid.
- Well-Defined:
- The steps in an algorithm must be precisely and unambiguously defined. Each step should be clear and not open to multiple interpretations.
- Deterministic:
- An algorithm should be deterministic meaning that given the same input and initial conditions, it will always produce the same result. There should be no unpredictability in its workings.
- Effective:
- An algorithm should be effective in solving the problem it is designed for, it should also use a reasonable amount of resources such as space and time.
- Feasibility:
- An algorithm should be feasible for practical use. It should work within a reasonable time and with the available resources.
Algorithm Efficiency
The efficiency of an algorithm is determined by whether it utilizes the available computational resources such as time and memory optimally. The performance is basically measured based on:
- Time Complexity
- Space Complexity
Time Complexity
Time complexity is used to measure the amount of time an algorithm takes to complete its task depending of the size of the input. Lower time complexity generally indicates better efficiency.
Space Complexity
Space complexity measures the amount of memory (space) an algorithm depending on size of the input. Lower space complexity also implies more efficient memory usage.
Generally, efficient algorithms aim to minimize both time and space complexity by striking a balance between the two to provide the most optimal performance. In some cases, however, there may be trade-offs depending on priorities of the program.